We propose BOSS (BootStrapping your Own SkillS), an approach that automatically learns to solve new long-horizon, complex, and meaningful tasks in new environments by growing a learned skill library with Large Language Model (LLM) supervision.
BOSS automatically learns to solve new long horizon, complex tasks in new environments by guiding an agent to grow a language-specified skill library tailored for the target environment during the skill bootstrapping phase. After skill bootstrapping, we can simply condition the learned policy on language descriptions for new tasks.
Training a BOSS agent consists of two phases: (1) it acquires a base repertoire of language-specified skills and (2) it practices chaining these skills into long-horizon behaviors in the skill bootstrapping phase. BOSS can then zero-shot execute novel natural language instructions describing complex long-horizon tasks.
To obtain a language-conditioned primitive skill policy, we pre-train a policy and critic with offline RL on a dataset of easier to collect short-horizon, language-annotated trajectories. In our experiments, we use Implicit Q-Learning (IQL) as it is performant and amenable to online fine-tuning.
We perform skill bootstrapping — the agent practices by interacting with the target environment, trying new skill chains, then adding them back into its skill repertoire for further bootstrapping. As a result, the agent learns increasingly long-horizon skills without requiring additional supervision beyond the initial set of skills.
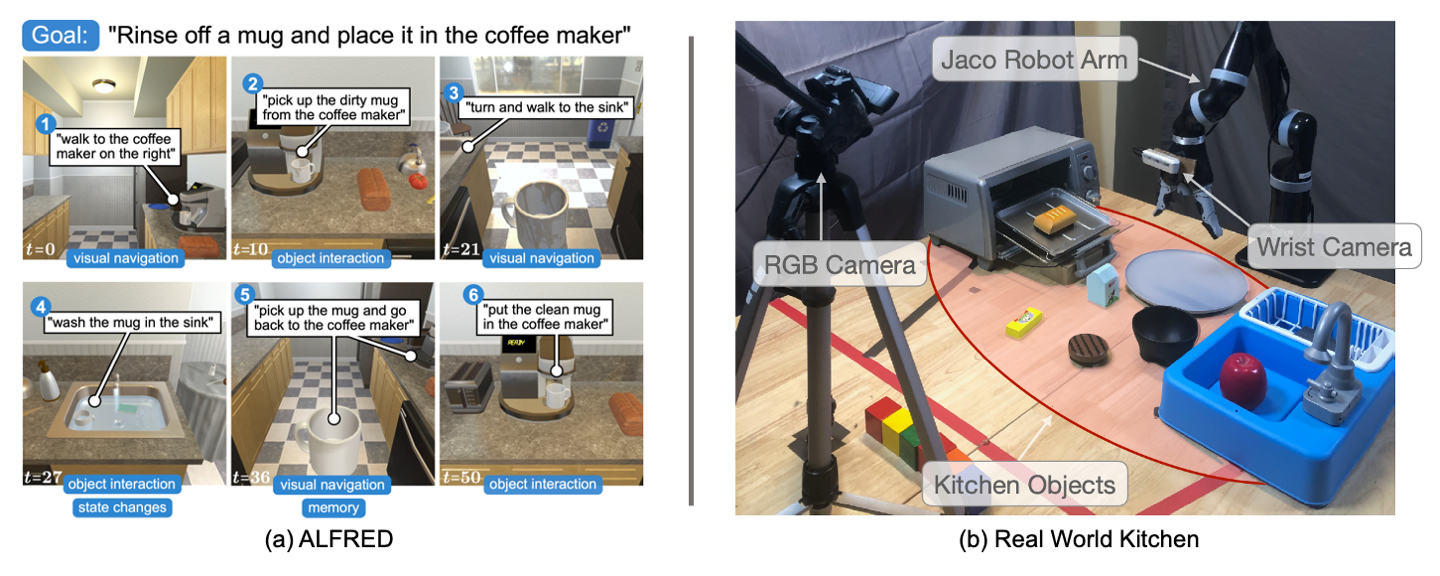
We perform online skill bootstrapping for 17 min of robot interaction time (15k timesteps) on an unseen environment configuration. Language-conditioned evaluations below. Comparison against ProgPrompt implemented with GPT-3.5.
Comparison against ProgPrompt implemented with GPT-3.5.

2/4 Skills Completed

4/4 Skills Completed
Task: "Clean the black bowl and put in the dish rack."

4/4 Skills Completed

4/4 Skills Completed
Task: "Clean the black bowl and put in the gray plate."
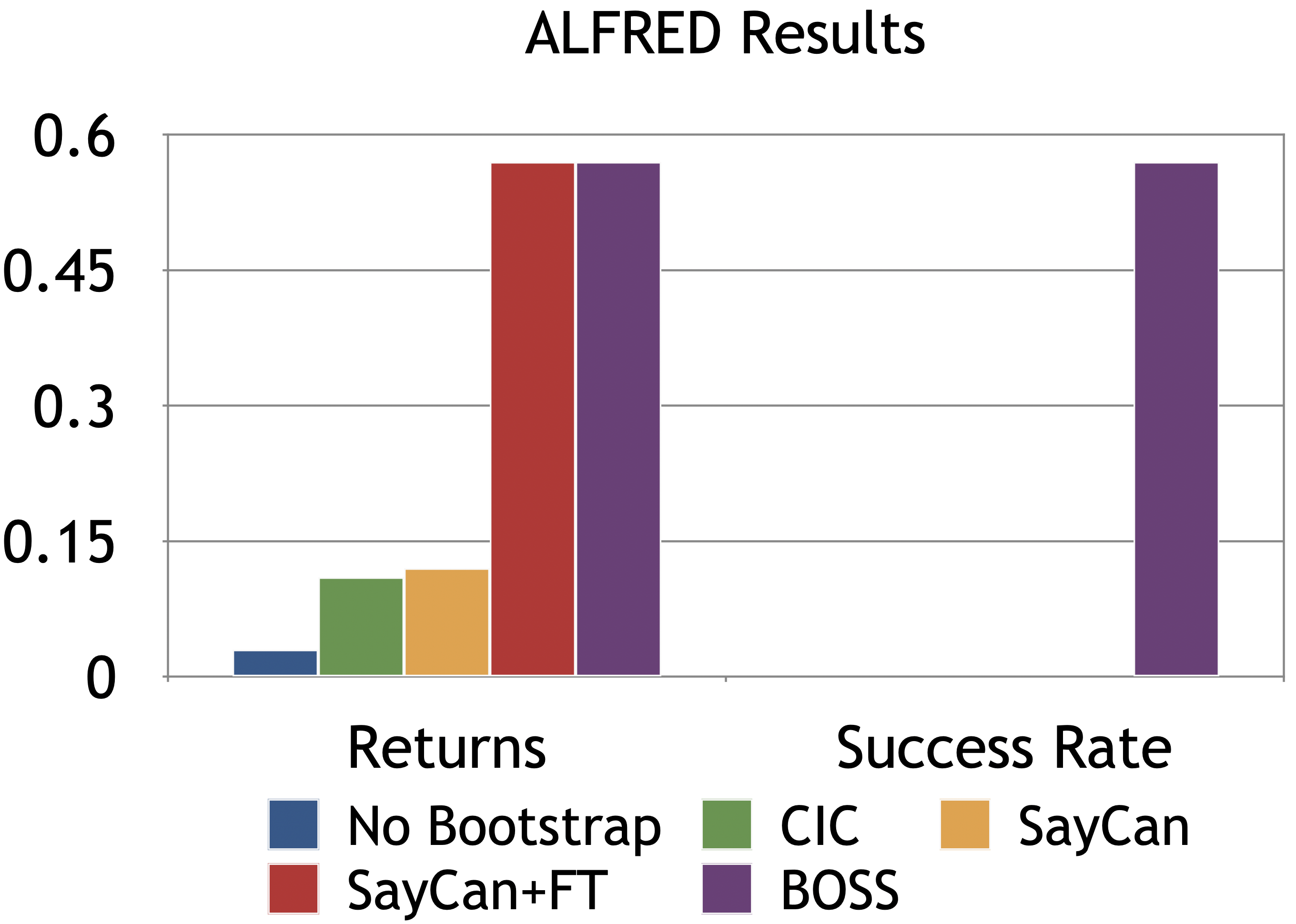
We show the cumulative returns and task success rates for zero-shot bootstrapped policies vs other methods. Even with SayCan policies are fine-tuned (SayCan+FT) for the same number of steps, the success rate is still 0 while BOSS is the only method that achieves non-zero success rates.
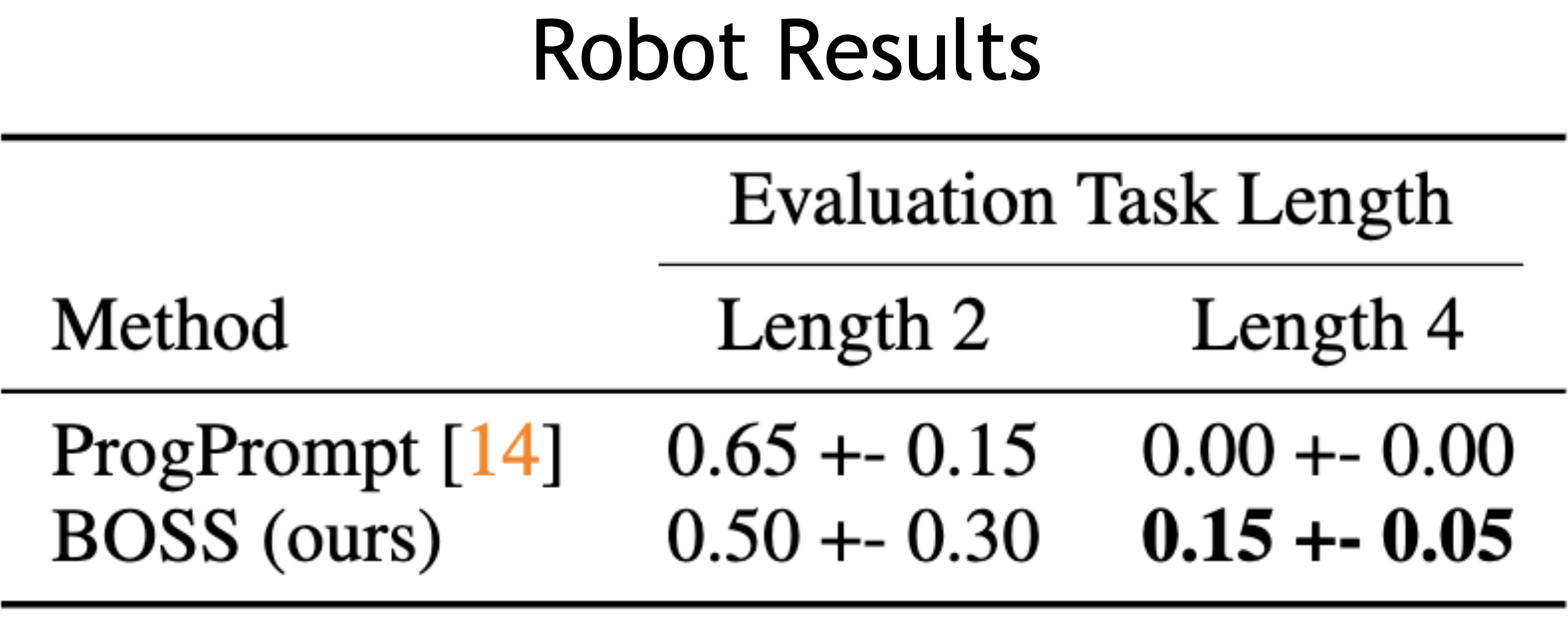
LLM-planning mechanisms like ProgPrompt have no standard fine-tuning procedure and therefore the policy is less effective at chaining skills together even when ProgPrompt breaks it down into step-by-step instructions.
We perform online skill bootstrapping in 40 unseen environment configurations for 500k timesteps.
 CIC
CIC
Completes no tasks as its unsupervised skill learning objective is unable to truly learn meaningful skills.
 SayCan
SayCan
Gets stuck while navigating; not even completing the first skill due to policy execution errors.
 BOSS
BOSS
Completes 2/2 sub-tasks through what it learned from skill bootstrapping in this environment.
Task: "Put the plunger in the sink."
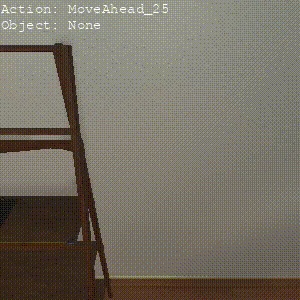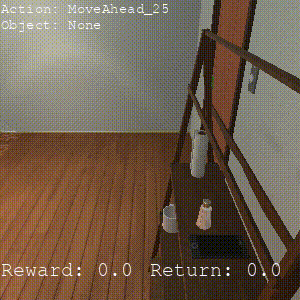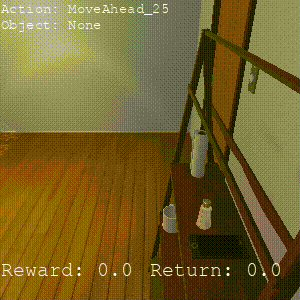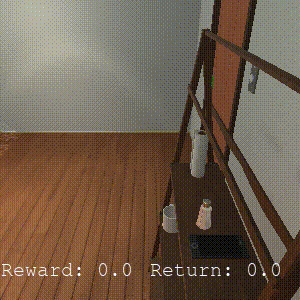 CIC
CIC
Completes 0 sub-tasks, generally learns more random behaviors that may get stuck navigating.
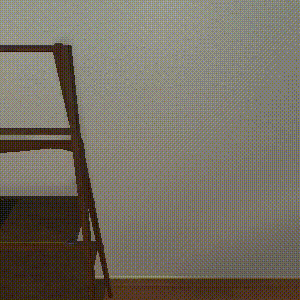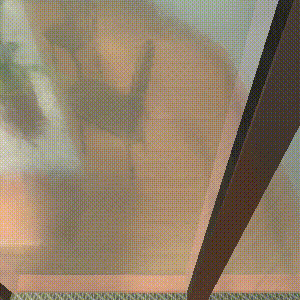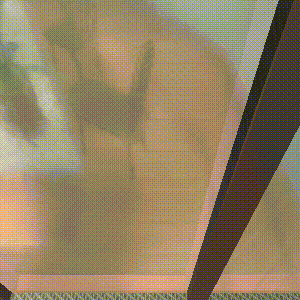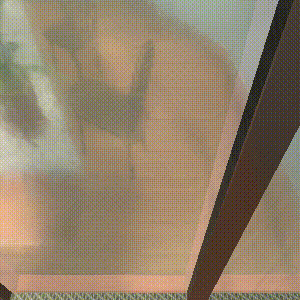 SayCan
SayCan
Completes 0 sub-tasks, the policy is confused by the incorrect instruction produced by the LLM.
 BOSS
BOSS
Completes 3/6 sub-tasks---picks up the potato at the end instead of the apple. Overall, still better than the baselines.
Task: "Put cooked apple slice on a counter."
We show the cumulative returns and task success rates for zero-shot bootstrapped policies vs other methods.
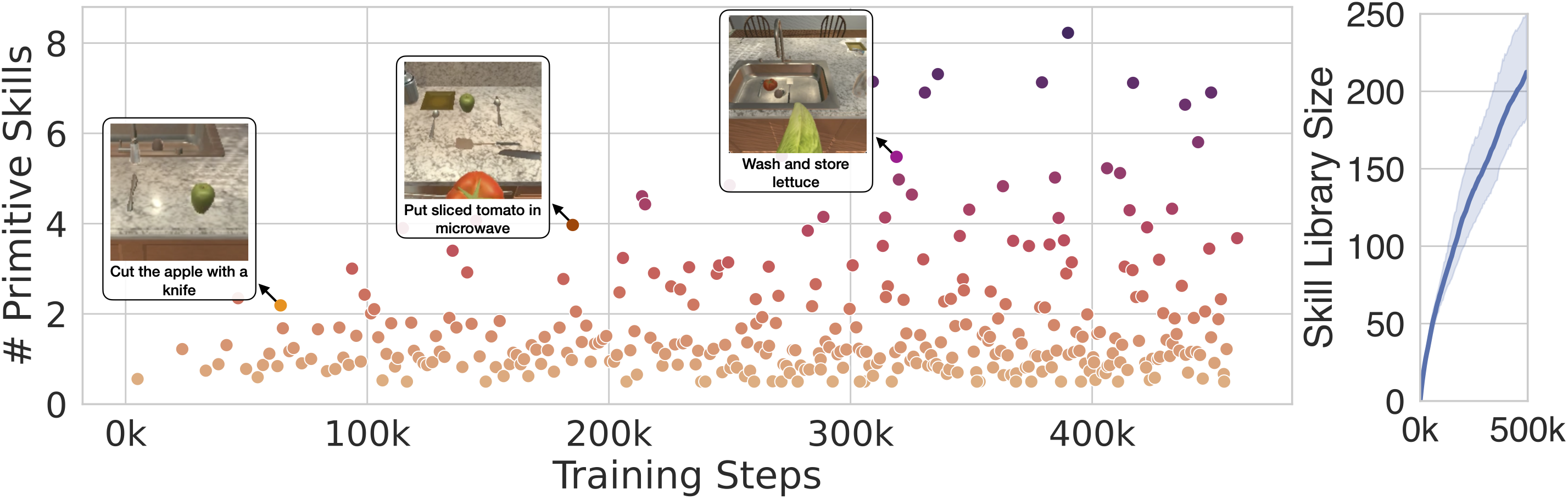
We plot the skill lengths of learned skills over time on the left. Skill bootstrapping is able to learn meaningful, longer horizon skills over time. On the right, we see that the skill library also grows over time.
The difference against SayCan and other similar LLM planning works is that they perform top-down planning of pre-trained/fixed policies (the policies can be learned or planning-based) directly in the target environment. BOSS, on the other hand, builds a skill library bottom-up tailored for the target environment and continually fine-tunes a learned agent on this skill library. This results in an agent which can better transition between skills and does not require an LLM planner at test-time to break down long-horizon tasks into primitive skill sequences for the agent to execute.
SPRINT focuses on pre-training policies for efficient adaptation given the intended target tasks. SPRINT uses an LLM to aggregate skills together with a higher-level task instruction, which we also use in BOSS. Meanwhile, BOSS is an algorithm that allows the agent to autonomously acquire new skills without knowing the intended target tasks in new environments.
We see two main limitations. The first is the need for environment resets between episodes, which we hope reset-free RL can help resolve in the future. The second is the requirement of data and sparse reward functions for the primitive skills which are used to compose all new learned skills. Data is difficult to collect and even sparse reward functions may be hard to acquire in the real world, so one way to allow BOSS to acquire even more skills would be to allow it to perform reward-free acquisition of new skills.
@inproceedings{
zhang2023bootstrap,
title={Bootstrap Your Own Skills: Learning to Solve New Tasks with Large Language Model Guidance},
author={Jesse Zhang and Jiahui Zhang and Karl Pertsch and Ziyi Liu and Xiang Ren and Minsuk Chang and Shao-Hua Sun and Joseph J Lim},
booktitle={7th Annual Conference on Robot Learning},
year={2023},
url={https://openreview.net/forum?id=a0mFRgadGO}
}