Abstract
We propose SPRINT, a scalable offline policy pre-training approach which substantially reduces the human effort needed for pre-training a diverse set of skills through relabling instructions with LLMs and an offline RL chaining objective.
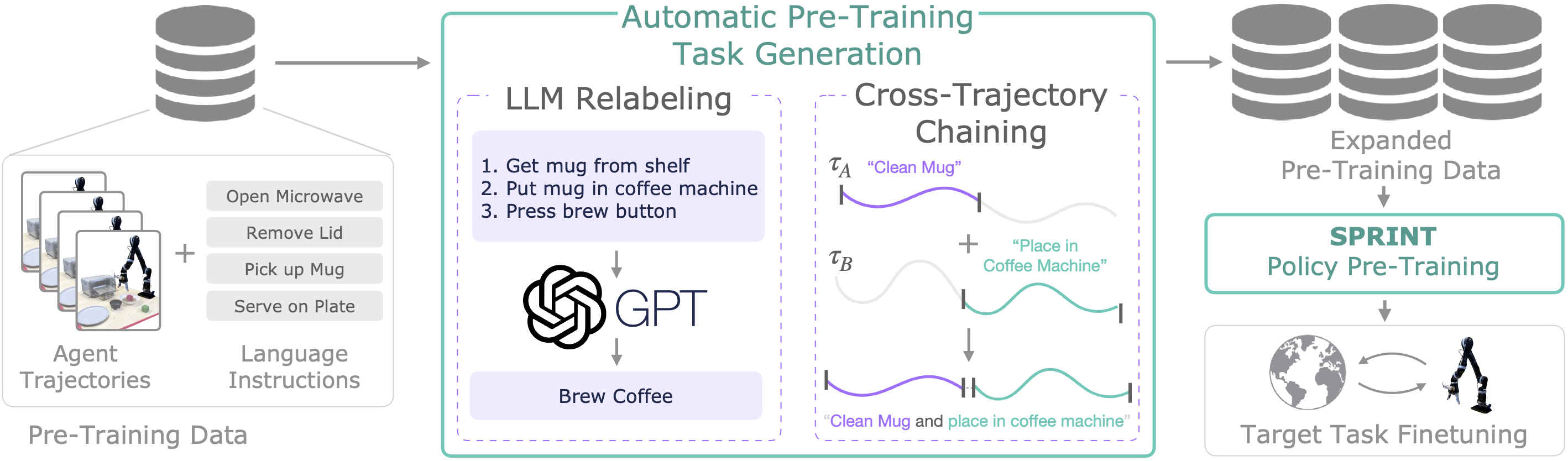
We propose SPRINT, a scalable offline policy pre-training approach which substantially reduces the human effort needed for pre-training a diverse set of skills through relabling instructions with LLMs and an offline RL chaining objective.
SPRINT equips policies with a diverse repertoire of skills via language-instruction-conditioned offline RL: given a natural language task description z, the policy π(a|s, z) is rewarded for successfully executing the instruction.
SPRINT introduces two approaches for increasing the scale and diversity of the pre-training task instructions without requiring additional costly human inputs. SPRINT pre-trains policies on the combined set of tasks and thereby equips them with a richer skill repertoire.
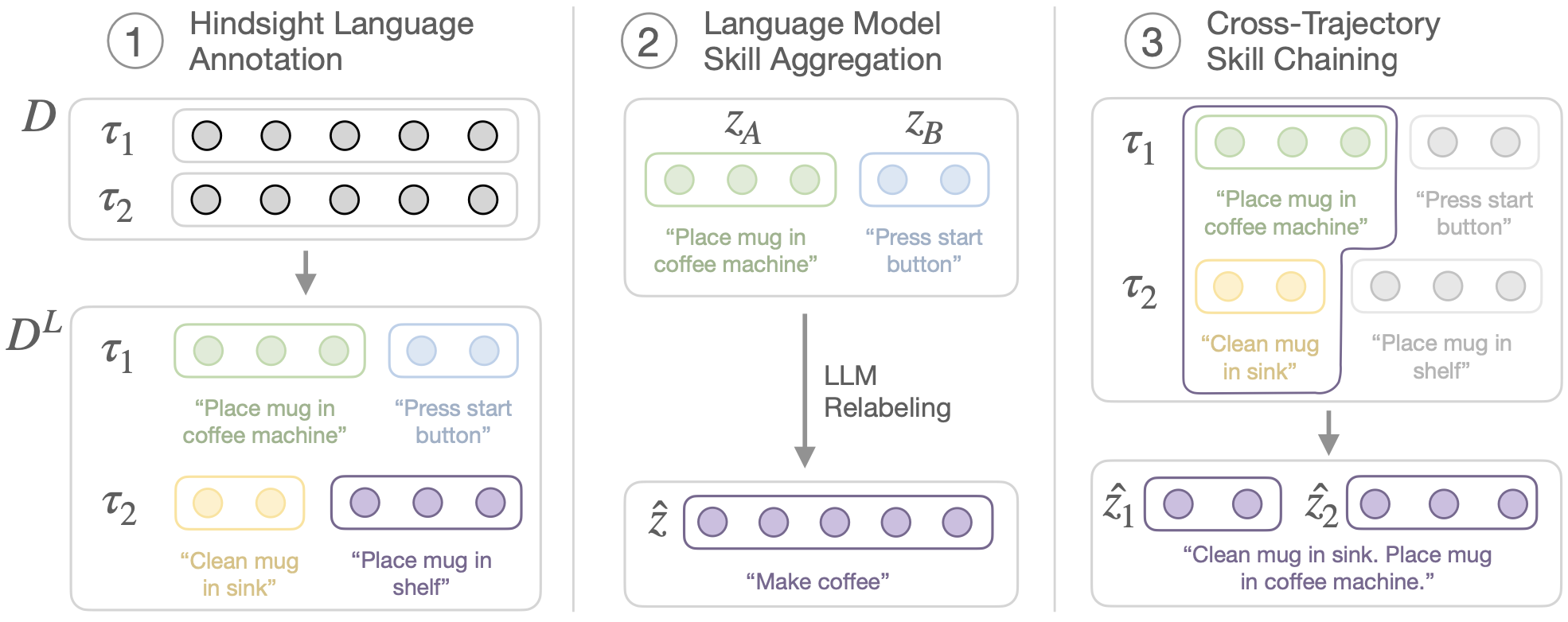
We assume the dataset provides a base set of language-annotated sub-trajectories which we can directly train on with offline RL and a sparse goal-reaching reward.
SPRINT leverages pre-trained, large language models to aggregate consecutive instructions into new tasks. These new, longer-horizon trajectories are also relabeled with sparse goal-reaching rewards.
SPRINT introduces an objective for skill-chaining via offline RL that generates novel instruction chains across different trajectories. We label the rewards of these new trajectories using a combination of concurrently trained Q-function and sparse goal-reaching rewards.
Evaluate on seen tasks.
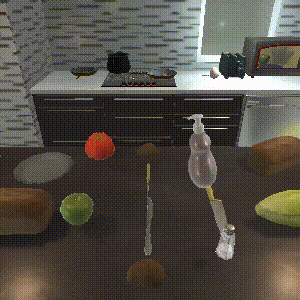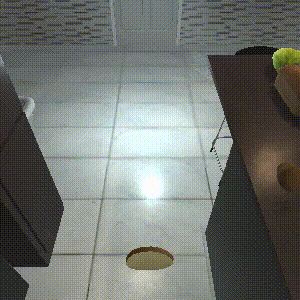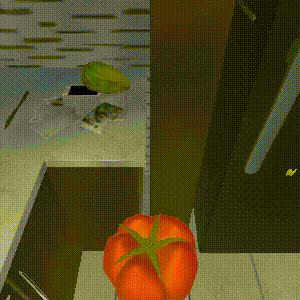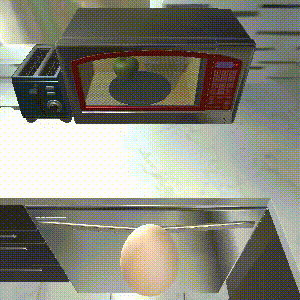 Episodic Transformer
Episodic Transformer
Completes 6/8 sub-tasks.
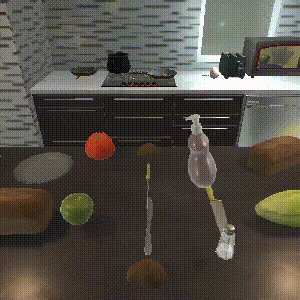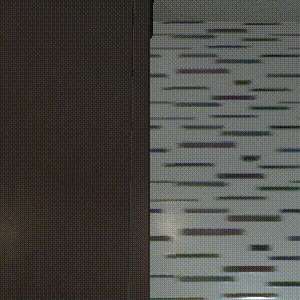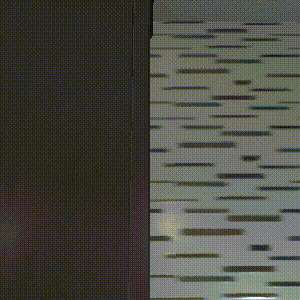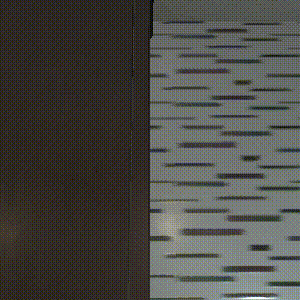 Actionable Models
Actionable Models
Completes 0/8 sub-tasks.
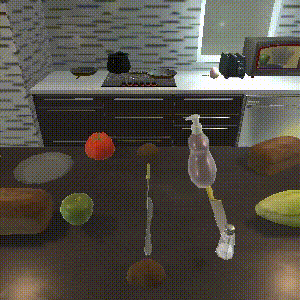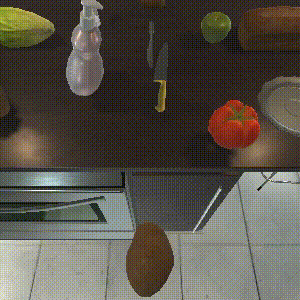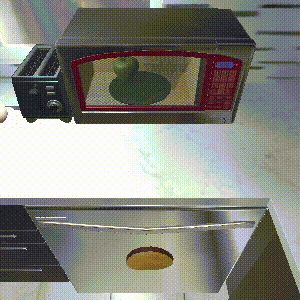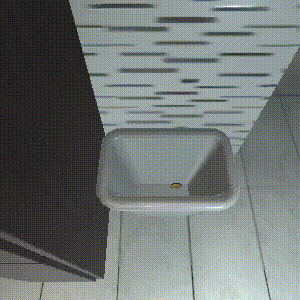 SPRINT
SPRINT
Completes 8/8 sub-tasks.
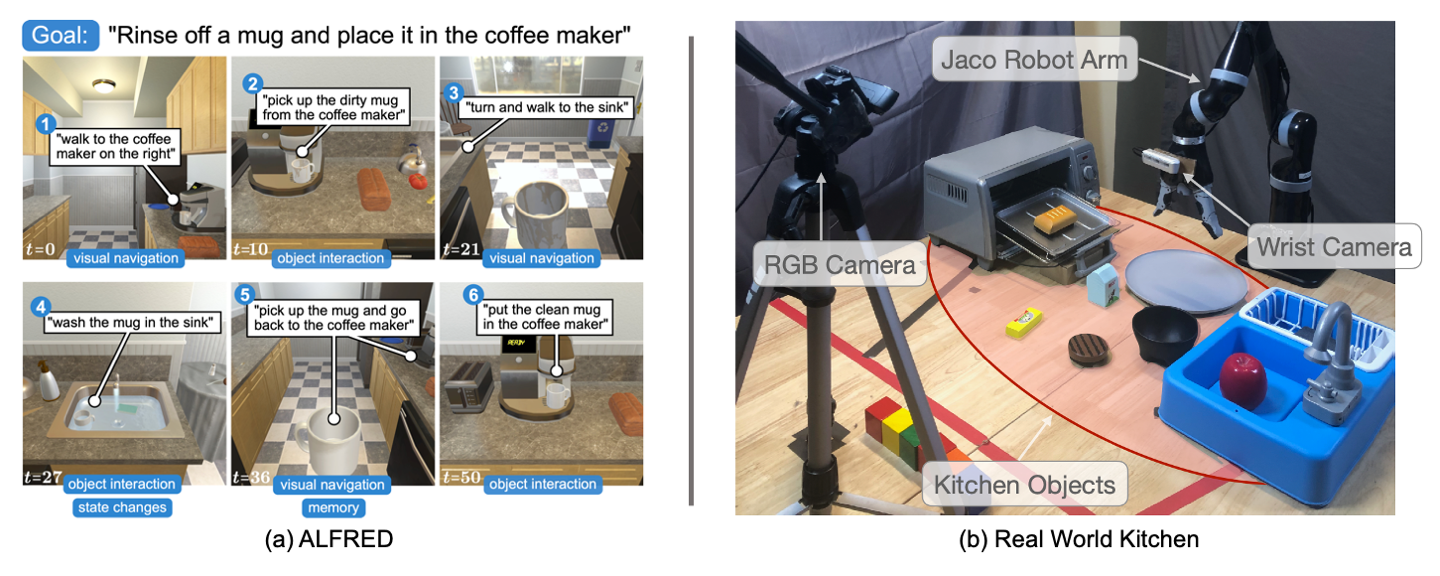
Task: "Throw away a microwaved slice of potato."
SPRINT outperforms the baselines on zero-shot evaluation. SPRINT finish all 8 sub-tasks, while Episodic Transformer, the state-of-the-art imitation learning baseline only finishes 6 sub-tasks. The other offline RL baseline, Actionable Models, does not finish any sub-tasks.
Finetune pre-trained policies with online RL for 50,000 timesteps.
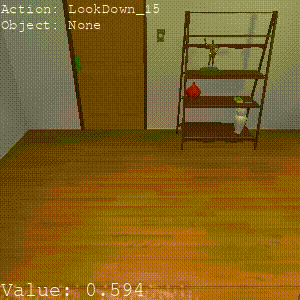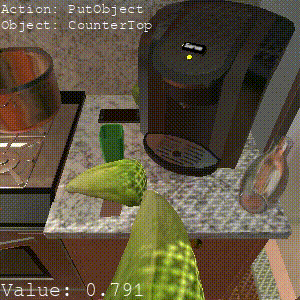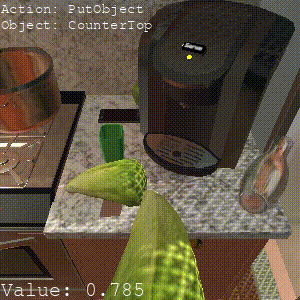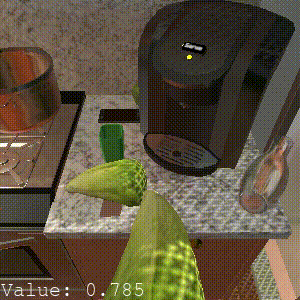 Episodic Transformer
Episodic Transformer
Completes 1/3 sub-tasks.
 Actionable Models
Actionable Models
Completes 0/3 sub-tasks.
 SPRINT
SPRINT
Completes 2/3 sub-tasks.
Task: "Put the chilled lettuce on the counter."
SPRINT also can benefit from online RL finetuning for unseen tasks. SPRINT finishes 2/3 sub-tasks, while Episodic Transformer only finishes 1 sub-task. And Actionable Models does not finish any sub-tasks.
We perform offline fine-tuning on 25 demonstrations for each task after pre-training.

Completes 4/8 sub-tasks.

Completes 8/8 sub-tasks.
Task: "Serve milk in the bowl and butter and baked bread in the plate."
We compare SPRINT with L-BC Composite, which is the best performing baseline. SPRINT accomplishes all the sub-tasks, while L-BC Composite fails to complete 4 sub-tasks. SPRINT is able to generalize to unseen tasks by finetuning with limited demonstrations. L-BC Composite performs well on the first 4 sub-tasks, but fails on the longer horizon sub-tasks.
@inproceedings{zhang2024sprint,
author={Zhang, Jesse and Pertsch, Karl and Zhang, Jiahui and Lim, Joseph J.},
booktitle={2024 IEEE International Conference on Robotics and Automation (ICRA)},
title={SPRINT: Scalable Policy Pre-Training via Language Instruction Relabeling},
year={2024},
pages={9168-9175},
doi={10.1109/ICRA57147.2024.10610606}}