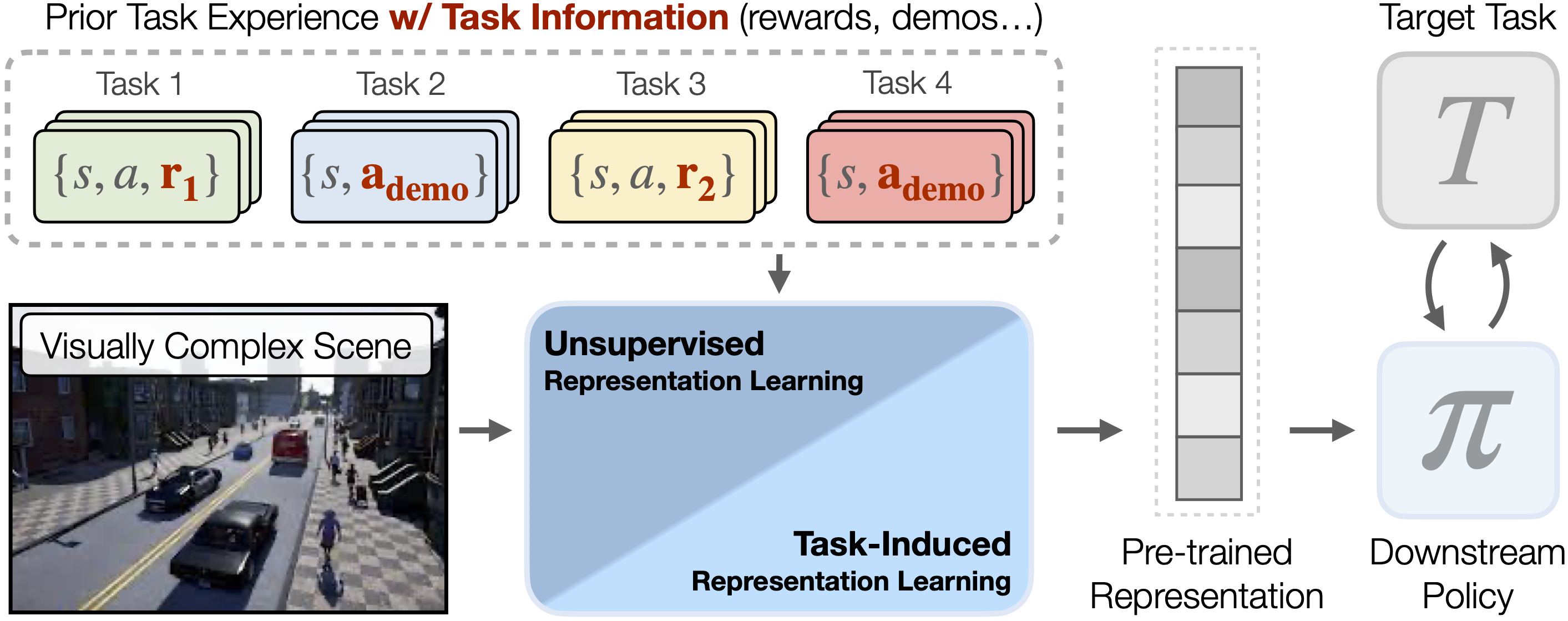
We evaluate the effectiveness of representation learning approaches for decision making in visually complex environments with distractors. Common unsupervised representation learning approaches, based e.g. on prediction or contrastive objectives, learn to model all information in a scene, including distractors, potentially impairing the agent's learning efficiency. We compare them to an alternative class of approaches, which we call task-induced representation learning. They leverage task information such as rewards or demonstrations from prior tasks to focus on task-relevant parts of the scene and ignore distractors. We evaluate unsupervised and task-induced representation learning on four visually complex environments, from Distracting DMControl to the CARLA driving simulator. For both, RL and imitation learning, we find that representation learning generally improves sample efficiency on unseen tasks even in visually complex scenes and that task-induced representations can double learning efficiency compared to unsupervised alternatives.
Task-Induced Representation Learning
Task-induced representation learning (TARP) leverages information from prior tasks to focus representation learning on the task-relevant aspects of the scene and ignore distractors. Below, we instantiate four objectives from the family of task-induced representation learning approaches that use reward or demonstration information from prior tasks for shaping the learned representations. This is not an exhaustive list of all TARP approaches and future work can e.g. investigate the use of language descriptions as an alternative form of task supervision.
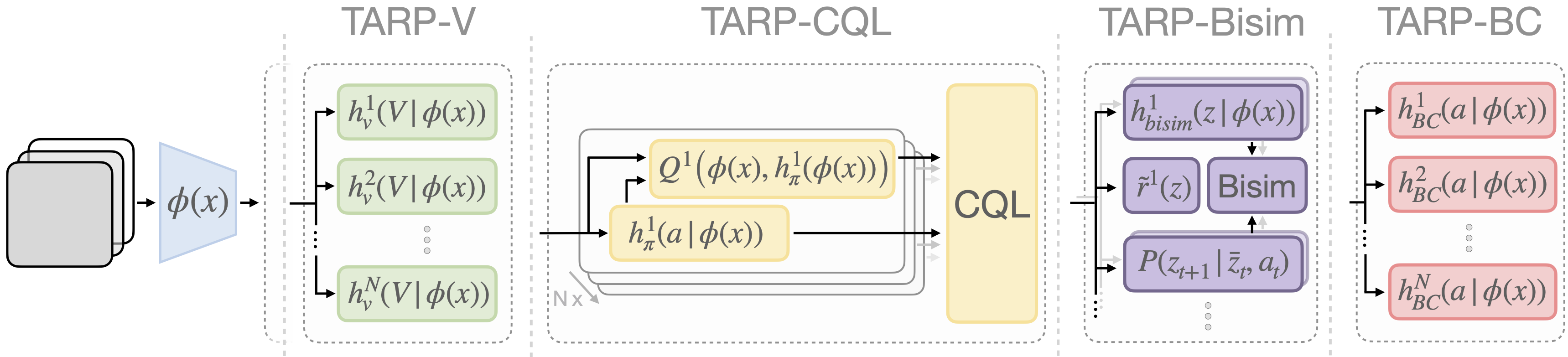
Value Prediction (TARP-V)
Trains a representation by estimating the future discounted return of the data collection policy. Trains a separate prediction head per task in the pre-training data, on top of a shared representation encoder.
Offline RL (TARP-CQL)
Performs multi-task offline RL on the pre-training data with separate policy heads and Q-functions for each pre-training task. All models share a common representation module.
Bisimulation (TARP-Bisim)
Uses a bisimulation objective that groups states based on their ``behavioral similarity'', measured as their expected future returns under arbitrary action sequences. We use separate heads for predicting the bisimulation distances and transition probabilities for each task. Following Zhang et al. (DBC) we add an auxiliary per-task reward prediction objective.
Imitation Learning (TARP-BC)
Trains a task-induced representation from data without reward annotation by directly imitating the data collection policy. We train a separate behavior cloning (BC) head for each task from the pre-training data, using a single shared representation encoder.
Environments
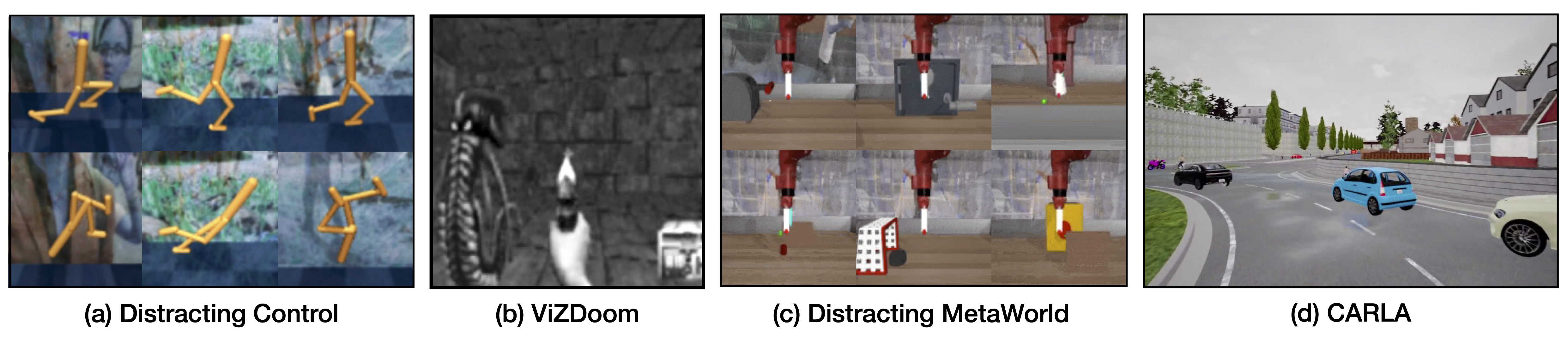
We compare unsupervised and task-induced representation learning approaches across four visually complex environments with substantial distractors. Distracting Control overlays natural videos in the background of the DMControl Walker task. ViZDoom is an ego shooter game with task-irrelevant details in the appearance of agents and enemies as well as texture and lighting features of the environment. Distracting MetaWorld also uses natural videos as distractors in the background, but has a larger set of available training / testing tasks, allowing us to investigate effects of task diversity in the training data. CARLA is a complex driving simulator with natural distractors like the vegetation, architecture, car model and make as well as weather phenomena.
Representation Transfer Results
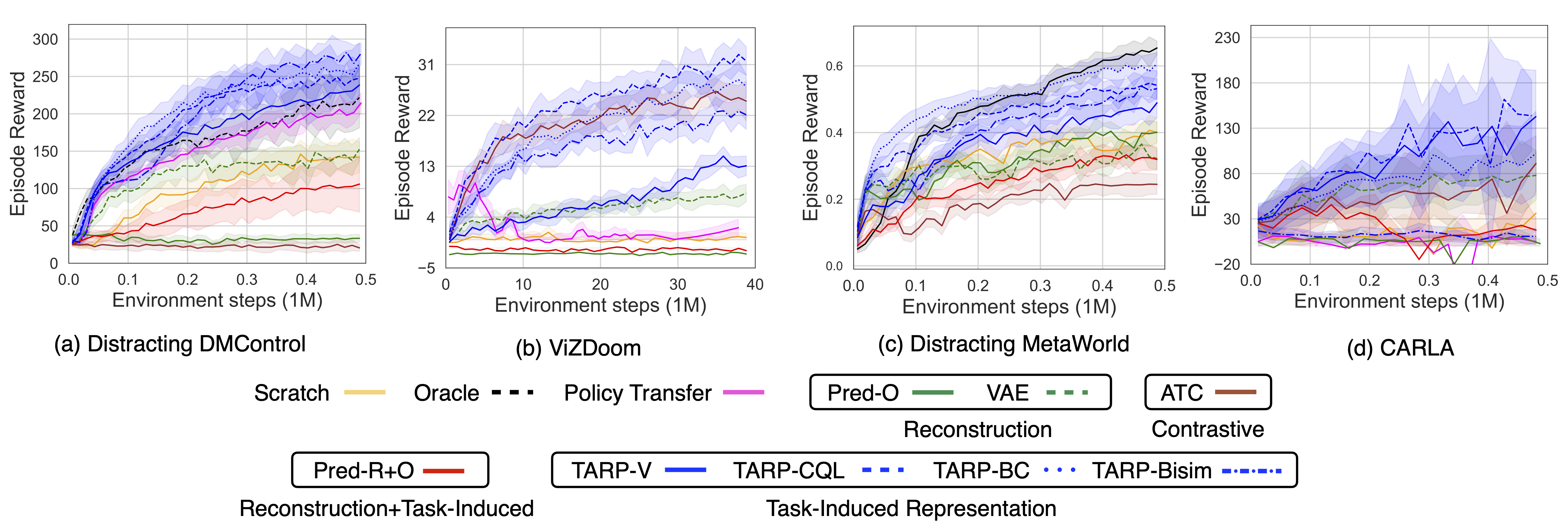
Representation transfer performance comparison. For each environment, we pre-train each representation learning approach on an offline dataset collected across multiple pre-training tasks. We then freeze the pre-trained representation and transfer it to a target policy, which we train to solve an unseen target task. We compare unsupervised representation learning approaches based on reconstruction / prediction (green) and contrastive learning (brown) to task-induced representation learning approaches (blue). Across all tested environments we find that representation learning improves learning efficiency on downstream tasks and that task-induced representation can lead to substantially more efficient learning than unsupervised alternatives. We obtain comparable results when finetuning the transferred representation during target task policy training (see paper, Section C).
For more detailed analysis experiments, downstream imitation learning results and best-practices for task-induced representation learning, see the paper, Section 5.
Visualizing the Learned Representations

We compute the input saliency maps for different representation learning approaches. Saliency maps visualize the average gradient magnitude for each input pixel with respect to the output representation and thus capture the contribution of each part of the input to the representation. We see that the task-induced representation (TARP-BC) can focus on the important aspects of the scene, such as the walker agent in distracting DMControl and other cars in CARLA. In contrast, the unsupervised approaches have high saliency values for scattered parts of the input and often represent task-irrelevant aspects such as changing background videos, buildings and trees, since they cannot differentiate task-relevant and irrelevant information. This supports our hypothesis that the improved learning efficiency of TARP approaches is a result of their ability to focus on modeling the task-relevant aspects of the scene.
Source Code
We have released our implementation in PyTorch on the github page. Check it out!
|