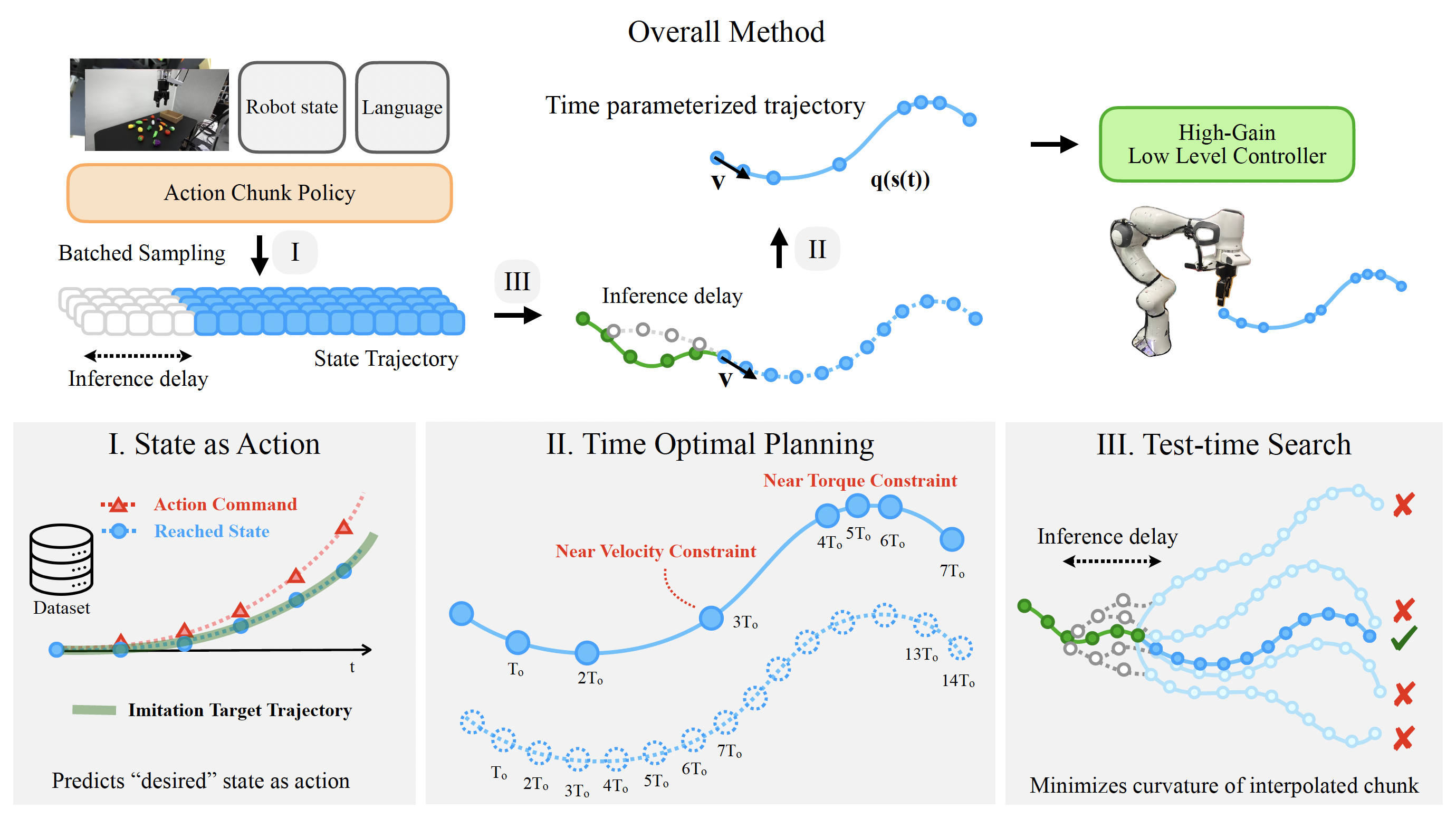
Time Optimal Execution of Action Chunk Policies Beyond Demonstration Speed

Abstract
Achieving both speed and accuracy is a central challenge for real-world robot manipulation. While recent imitation learning approaches, including vision-language-action (VLA) models, have achieved remarkable precision and generalization, their execution speed is often limited by slow demonstration via teleoperation and by inference latency. In this work, we introduce a method to accelerate any imitation policy that predicts action chunks, enabling speeds that surpass those of the original demonstration. A naive approach of simply increasing the execution frequency of predicted actions leads to significant state errors and task failure, as it alters the underlying transition dynamics and encounters physical reachability constraints over shorter time horizons. These errors are further amplified by misaligned actions based on outdated robot state when using asynchronous inference to accelerate execution. Our method RACE address these challenges with a three-part solution: 1) using desired states as imitation targets instead of commanded actions, 2) replanning the timing of action chunks to execute them as fast as the robot's physical limits allow, and 3) employing a test-time search for an aligned action chunk that maximizes controllability from the current state. Through extensive experiments in both simulation and the real world, we show that our method achieves up to a 4x acceleration over the original policy while maintaining a high success rate.
Method
RACE (Reachability-aware Accelerated Chunk Execution) addresses the challenges of policy acceleration with a three-part solution. First, it reformulates the imitation problem to predict desired reached states instead of action commands, making the policy robust to changes in execution timing. Second, it uses time-optimal planning to re-parameterize the predicted state trajectory, ensuring it's dynamically feasible and respects the robot's physical torque and velocity limits. Finally, to handle inference delays, it employs a test-time search to select the future action chunk that forms the smoothest, most controllable path from the robot's current state.
Results
Pareto-Optimal Performance
We evaluate RACE across both simulation and real-world tasks. RACE consistently achieves a better trade-off between speed and success rate. The plots below show that naive acceleration methods suffer a sharp drop in success rate as speed increases, especially on high-precision tasks. In contrast, RACE maintains a high success rate while significantly increasing the execution speed, achieving Pareto-optimal performance.
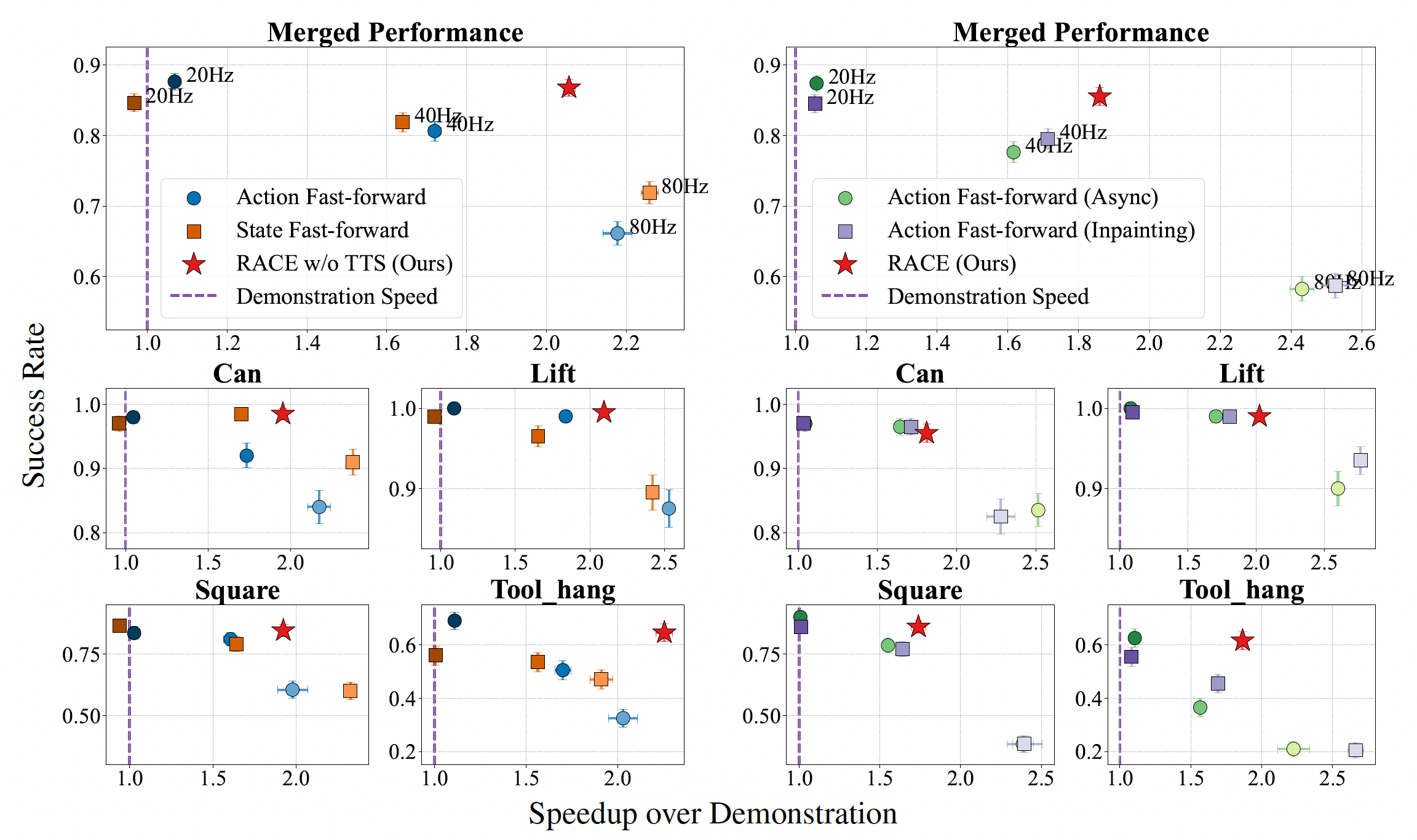
Figure 4: Simulation Results. RACE (red star) achieves up to 2× speedup in simulation without degrading success rate, especially on precise tasks like Square and Tool Hang.
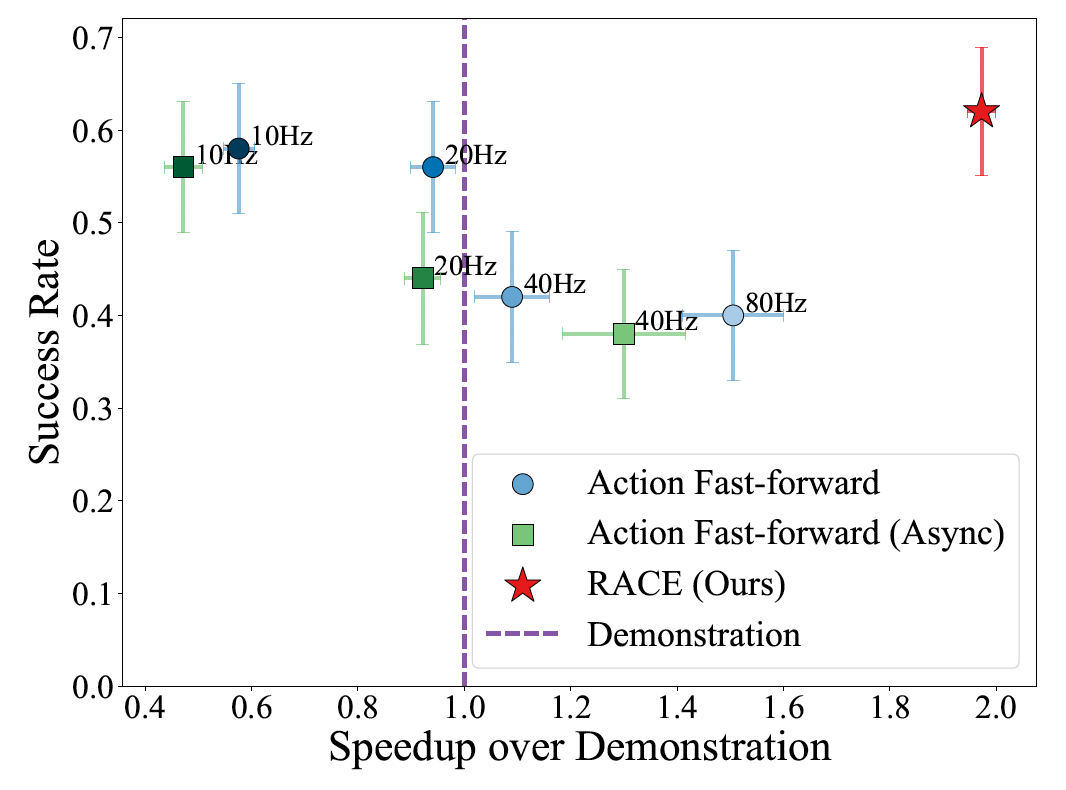
Figure 5: Real-World Precision Task (Door Insertion). RACE achieves far greater speedup than baselines while maintaining the original policy's success rate.
Simulation Rollout Videos
Below we show rollout videos from simulation tasks, comparing RACE with 20Hz baseline approaches across different manipulation tasks.
RACE (Ours)
Time-optimal execution
20Hz Baseline
Fixed 20Hz control
RACE (Ours)
Time-optimal execution
20Hz Baseline
Fixed 20Hz control
RACE (Ours)
Time-optimal execution
20Hz Baseline
Fixed 20Hz control
RACE (Ours)
Time-optimal execution
20Hz Baseline
Fixed 20Hz control
Real-World Robot Videos
We validate RACE on real robotic manipulation tasks. The videos below demonstrate that RACE achieves significantly faster execution while maintaining high success rates compared to fixed-frequency baselines.
High-Precision Task: Door Insertion
RACE maintains success rate while executing 4× faster than 10Hz baseline.
RACE (Ours) - Fast & Successful ✓
40Hz - Often Fails ✗
10Hz - Slow but Works
Throughput Task: Fruit Packaging
RACE completes more sub-tasks in the same time while maintaining accuracy.
RACE (Ours) - Fast & Precise ✓
45Hz - Misses Objects ✗
15Hz - Lower Throughput
Throughput Task: Trash Cleaning
RACE efficiently clears more items while baselines struggle with accuracy at higher speeds.
RACE (Ours) - Fast & Reliable ✓
45Hz - Lower Success ✗
15Hz - Slower
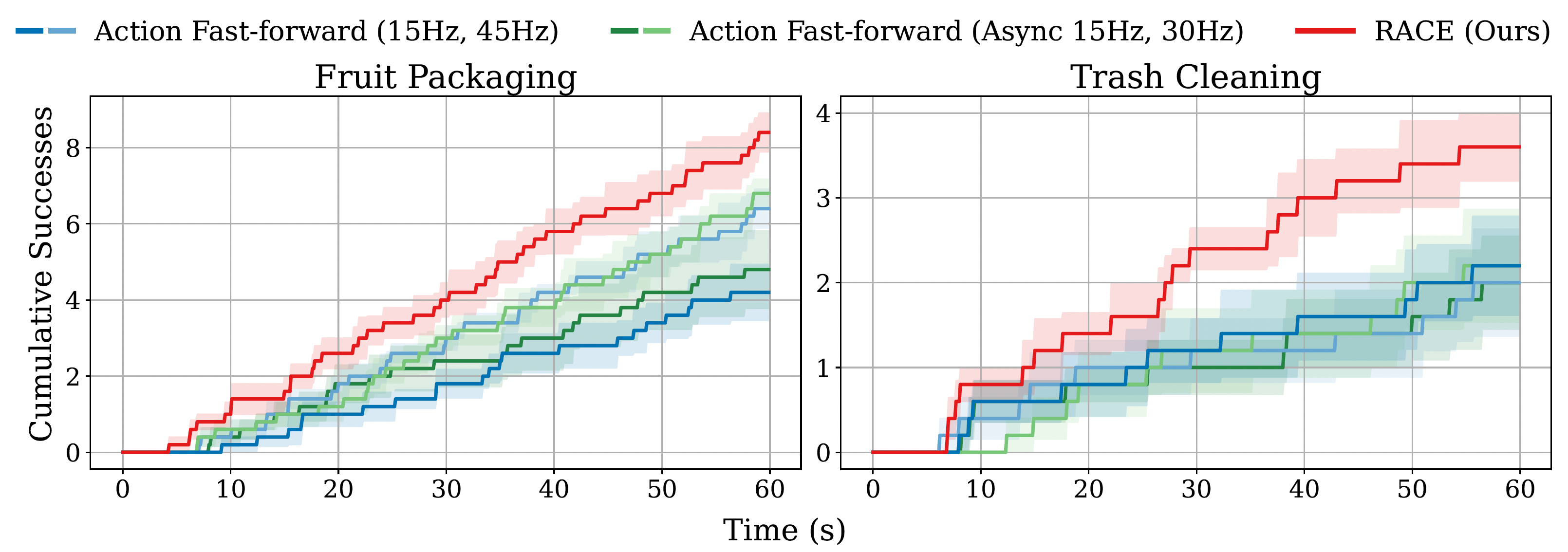
Figure 6: Throughput Results. RACE (red line) achieves a higher number of cumulative successes over time compared to all baselines.
Dynamic Task: Conveyor Belt Pick
We additionally evaluate RACE in a dynamic setting where the robot must pick a moving object on a conveyor belt. Compared to fixed-frequency baselines, RACE maintains substantially higher success rates and stronger speedup, including at an unseen 2.5× conveyor speed.
RACE (Ours) - Best robustness under dynamic motion
Base 45Hz - Faster, unstable on moving objects
Base 15Hz - Stable but too slow
| Method | SR | Time (s) | SOD |
|---|---|---|---|
| Base (15Hz) | 0.03 | 21.3 | 0.61× |
| Base (45Hz) | 0.27 | 15.4 | 0.84× |
| RACE (Ours) | 0.63 | 9.8 | 1.32× |
RACE (Ours) - Maintains strong success at unseen speed
Base 45Hz - Near-zero success
Base 15Hz - Near-zero success
| Method | SR | Time (s) | SOD |
|---|---|---|---|
| Base (15Hz) | 0.00 | - | - |
| Base (45Hz) | 0.00 | - | - |
| RACE (Ours) | 0.53 | 6.4 | 2.02× |
Each clip is concatenated from 20 dynamic-task episodes for easier side-by-side comparison.
Ablation Study
We performed ablation studies to validate the contributions of each component of RACE. The results show that time-optimal planning is crucial for minimizing state errors that accumulate in naive acceleration methods (left). Additionally, our test-time search (TTS) effectively improves path smoothness and controllability, leading to lower joint error and higher throughput, especially in the presence of inference delays (right).
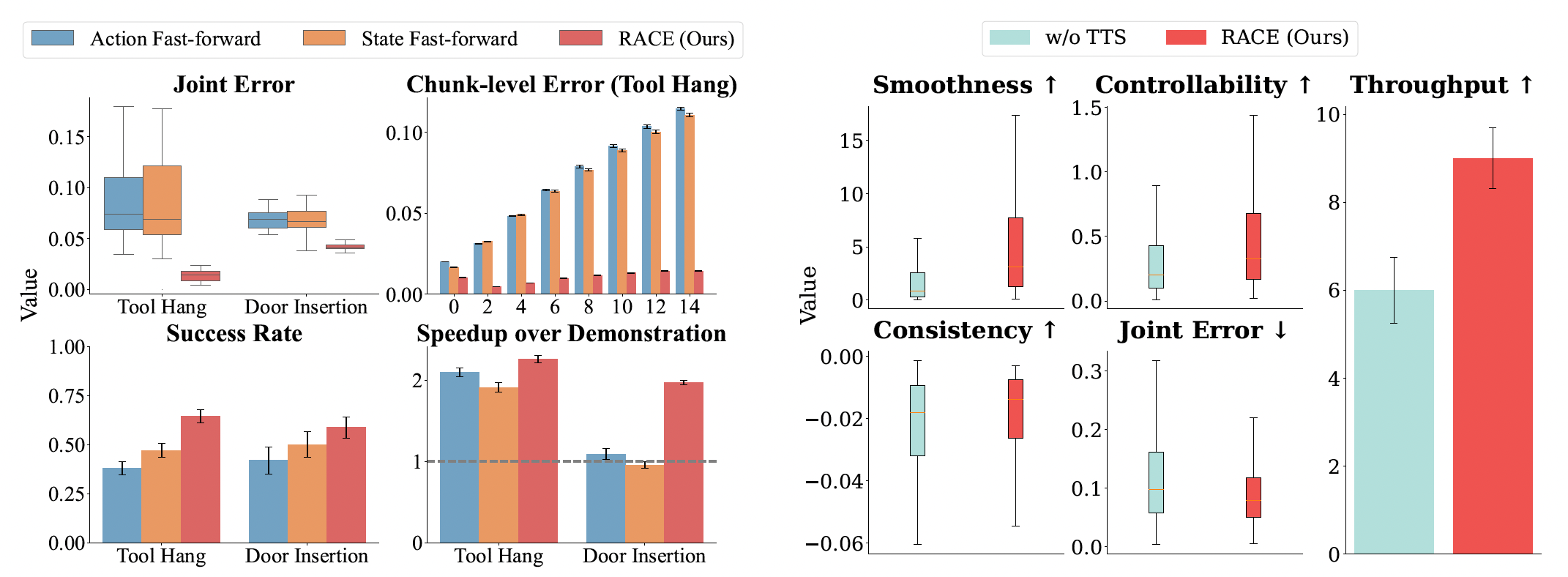
Figure 7: Ablation Results. (a) Time-optimal planning in RACE reduces joint error and improves success/speedup. (b) Test-time search improves smoothness, controllability, and throughput.
Comparison with SAIL
We additionally compare RACE against SAIL, a recent method for faster-than-demonstration execution. Across Robomimic tasks, RACE achieves consistently higher success rates while maintaining strong speedup, with especially large gains on precision-demanding tasks.
| Task | SAIL SR ↑ | SAIL SOD ↑ | RACE SR ↑ | RACE SOD ↑ |
|---|---|---|---|---|
| Lift | 0.930 | 2.520 | 0.995 | 2.068 |
| Can | 0.890 | 1.970 | 0.965 | 1.805 |
| Square | 0.750 | 1.620 | 0.805 | 1.819 |
| Tool Hang | 0.610 | 0.940 | 0.715 | 2.053 |
Table 1: SAIL vs. RACE. RACE improves SR across all tasks and shows stronger speedup on high-precision tasks.
Reference: SAIL paper (arXiv) and project page.
BibTeX
@inproceedings{kim2026race,
title={Time Optimal Execution of Action Chunk Policies Beyond Demonstration Speed},
author={Kim, Sunwoo and Kim, Jeongjun and Lim, Joseph J.},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}